
As a Senior Software Engineer and lead of the Predictive Technology crew, Caroline Rodewig works to expand the scope and quality of FlightAware's predictive applications.
FlightAware’s Predictive Technologies team is responsible for training and serving machine learning models to predict key flight elements. Our primary product is ETA predictions – en-route landing time (ON) and gate arrival time (IN) predictions.
Model Server
Motivation
Producing real-time predictions requires two components: feature vector building and model evaluation (aka inference).
Our original infrastructure (the Python streamer) handled both of these in one place. It followed our flight data feed to build feature vectors and evaluated those vectors on models it loaded into memory. The streamer was not performant enough to run for all the airports we wished to make predictions for, so we ran many copies of it, with each streamer responsible for a subset of airports.
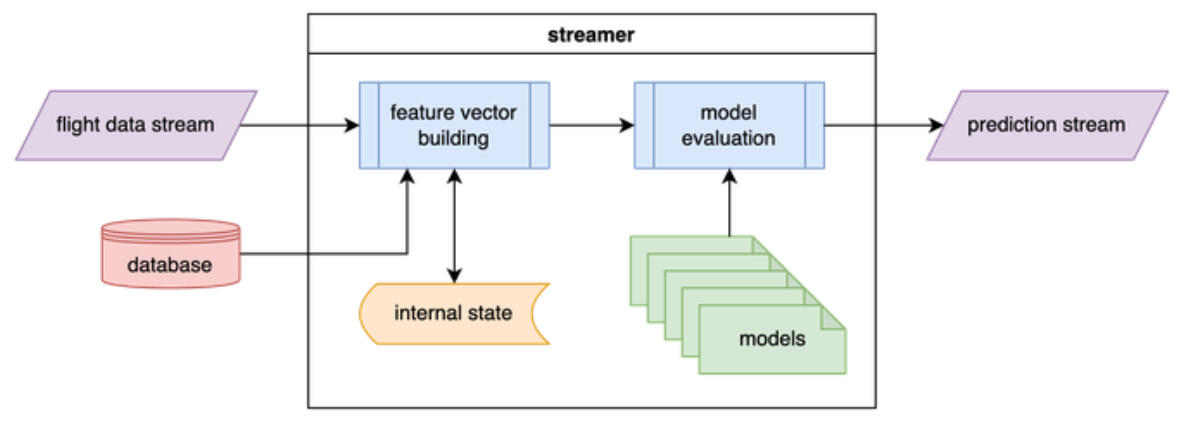
While this pattern worked for us for several years, it was not a good long-term solution for several reasons:
1. It was inefficient. Each streamer had to read the entire flight data stream to pick out data for a tiny fraction of flights. Each streamer was responsible for about 20 destination airports. FlightAware tracks flights into over 20,000 distinct destination airports, and 400 of those destinations average at least 100 flights per day. In the best-case scenario, each streamer was making use of only 5% of the flight data it read. Feature computation that could be cached across airports was recomputed instead. For example, we loaded GFS weather data on each streamer independently, when a lot of that processing could have been reused across destinations. It’s typically much faster to perform inference on feature vectors in parallel rather than sequentially – i.e., by batching several feature vectors and evaluating them together. Our architecture could only perform inference sequentially, and it would have taken significant work to change it to perform batch inferences.
2. It was difficult to manage. We were running 60 streamer instances (across 12 hosts) in each data center (120 streamers total). Managing this was unwieldy, and it added complexity to deployments, which took around 20 minutes as we staggered the restarts across hosts. It also just used a lot of hardware inefficiently. Delegating airports to streamers was a manual process and was prone to imbalance. It was possible that one streamer would run 20 huge airports and fall behind while another streamer was barely loaded with 20 tiny airports. Correcting these imbalances required manually copying model files to different hosts and hoping that the streamers would keep up when they loaded the new suite of models.
3. A future neural network model release would exacerbate both problems described above. We were working on training a single neural network ETA model to replace the many LightGBM models. Testing showed that it would increase our predictions' stability but would be significantly slower to evaluate. In the best-case scenario, inference on a neural network would take five times as long as a LightGBM model. To one-for-one replace our LightGBM models with a neural network, we would have needed to double or triple our hardware – an unacceptable solution.
4. It tied us to languages with strong machine learning support. The streamer needed to be written in a language which supported loading and evaluating a model; for the most part, that tied us to Python. As we added new model features, the performance limitations of Python became fairly apparent.
Solution
These problems were far from unique to our infrastructure. A typical pattern within the MLOps world is to split apart feature vector building and model evaluation. Rather than loading models into memory directly, the streamer would call out to a model server, which would perform feature vector batching and inference.
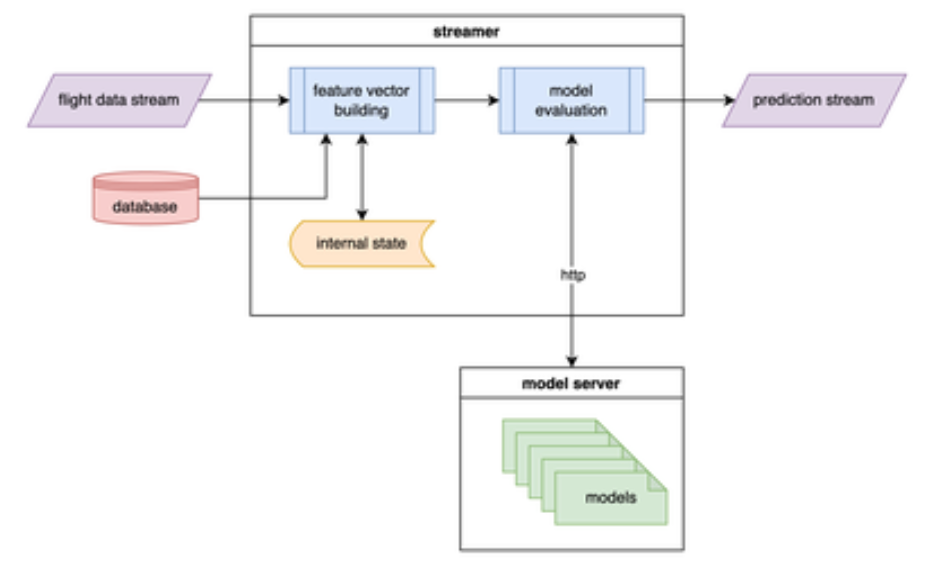
This architecture has a variety of benefits:
- It enables independent scaling of feature vector building and model evaluation. For example, if model evaluation becomes more expensive, we can scale up the model server pool while leaving the number of streamers the same. We can even make scaling automatic by monitoring for increased model server response time.
- It removes the language dependency from feature vector building. Rather than requiring machine learning language support, the streamers just need to be able to make asynchronous HTTP/gRPC requests.
- It provides native dynamic batching support. As streamers make requests to the model server, it will dynamically assemble batches of requests to evaluate. The streamers don’t need any knowledge of this, which keeps them simple.
- It moves us in the direction of service-based architecture. FlightAware’s Web and Backend teams have also been working on stack improvements with microservices, and recently completed a language assessment to begin development in earnest.
Triton Inference Server
We decided to use NVIDIA’s Triton Inference Server as our model server. It’s highly performant, well-optimized, and is particularly well-suited to our practice of training many models per product. It also supports a wide variety of machine learning and deep learning model backends, including TensorFlow, PyTorch, ONNX Runtime, and tree-based models (including XGBoost and LightGBM).
Triton is much simpler to set up than most other model servers; all you need to do is provide it with one or more properly configured model repositories. The repository must have a flat structure and each model directory must contain configuration for that model.

Triton supports API access through both HTTP and gRPC, using a standard API defined by KServe. The available APIs include:
- check server health
- list models available to the server and whether or not they're loaded
- load model so that it can be used for inference
- perform inference with provided input vector
- view model configuration
- view model statistics, including number of calls, total duration spent performing inference, and the time the last inference was made
Model ensembles
One of the key features of Triton is the ability to define an ensemble model. An ensemble is simply a DAG of other models within Triton, but which otherwise has the same properties as any other model. Independent steps can be run in parallel, and the output of one model can even be piped to the input of another model.
This is particularly useful for our LightGBM ETA models because the ON and IN models use exactly the same features. Using an ensemble allows us to send one request and get two predictions back, cutting the total number of requests we need to make in half.
Here’s an example ETAs ensemble model configuration. Note that the same input is sent to both ON and IN models and that both model outputs are made available in the final output.
name: "v3.0.0-KHOU"
platform: "ensemble"
max_batch_size : 10000
input [
{
name: "INPUT"
data_type: TYPE_FP32
dims: [ 515 ]
}
]
output [
{
name: "EON"
data_type: TYPE_FP32
dims: [ 1 ]
},
{
name: "EIN"
data_type: TYPE_FP32
dims: [ 1 ]
}
]
ensemble_scheduling {
step [
{
model_name: "v3.0.0-KHOU-eon"
model_version: 1
input_map {
key: "X"
value: "INPUT"
}
output_map {
key: "variable"
value: "EON"
}
},
{
model_name: "v3.0.0-KHOU-ein"
model_version: 1
input_map {
key: "X"
value: "INPUT"
}
output_map {
key: "variable"
value: "EIN"
}
}
]
} Running Triton
We decided to run Triton in Kubernetes to take advantage of Kubernetes’ scaling and failover capabilities. Our deployment ended up being a simplified version of Triton’s Helm chart, with a load balancer service and a deployment of Triton pods. Each pod maintains its own volume with a model repository that is copied in on pod startup.
This service was FlightAware’s first production-critical service deployed on Kubernetes, so keeping things simple was top-priority. In the future, we intend to add:
- A persistent volume with a model repository that is used by all Triton pods, and which can be deployed to via automation tools like Github Actions.
- Horizontal pod autoscaling based on the servers' response and inference times. Our day-to-day load is typically stable but having autoscaling would protect us in case of air traffic spikes and general traffic growth.
Other model server contenders
There are a number of other open source model servers available, including Seldon Core, Ray Serve, TensorFlow Serving, TorchServe, BentoML, and KServe. We wanted a platform that was backend-agnostic and scaleable, so we compared Triton against Seldon Core and Ray Serve.
Seldon Core
Seldon Core is a Kubernetes-native solution that is used pretty broadly in MLOps infrastructures. It offers many neat features, including outlier detection, A/B testing, and sophisticated graph-based model ensembling.
Its main downside is its complexity – it has a steep learning curve, and I wasn’t convinced that the complexity/feature tradeoff would come out in our favor. Additionally, it is poorly suited to our practice of training hundreds/thousands of models. It seems targeted at running one model per Kubernetes pod (we would run out of pods pretty quickly).
Ray Serve
Ray is a framework that is designed to scale Python applications – it feels a lot like ‘Kubernetes for Python.’ It allows you to submit jobs to a cluster, scale them up and down, and monitor them easily. We are already using Ray for training certain models and are hoping to expand its use. Ray Serve is a library built on top of Ray which provides some conveniences when it comes to model serving.
While Ray Serve could have worked for us, to use it we would have had to implement a lot of infrastructure that other platforms already offer – rolling our own platform seemed foolish when there are other, more sophisticated options out there.
Streamer Rewrite
Motivation
The naive approach to using the model server was to simply replace the streamers' in-memory model evaluation with an HTTP call. Unfortunately, this approach was unable to keep up in real-time, even when running for only twenty airports.
You might be thinking, ‘but shouldn’t the model server make inference faster? If it doesn’t, why bother with all this?'
The answer to that is that Triton is optimized for handling many parallel requests. Each individual request will take longer to compute, but Triton can evaluate models massively in parallel (think of those 10k batch sizes). The streamers did use async for building feature vectors but were limited to processing a single input line at a time, which meant that they would only send one inference request at a time.
Changing this architecture would have required a fairly major rewrite. It would have been possible, and if there hadn’t been other things we wanted to change about the streamer, it’s what we would have done. The most efficient way to use Triton is to make ON and IN predictions simultaneously, in one request. However, our streamers were optimized for producing either ON or IN predictions, but not at the same time. Changing this would have required additional streamer rearchitecting as well as changes to the deployment process. In addition, we had been struggling with the performance of the streamer (and generally the limitations of Python). The ‘hacks’ that made it fast enough for production had also made the code much more difficult to reason about. The code would have only become more complex when reworked to send parallel inference requests. We had already been considering rewriting the streamer in a faster language, especially as we considered adding more complex feature sets to our models. It would be trivial to validate that a rewritten streamer is accurate, as we could simply compare feature vectors between our ETL and different streamer implementations. Ultimately, a streamer rewrite was on the horizon, independent of the new model server. Why waste time on a massive overhaul of the Python streamer now, when we wanted to rewrite it soon anyway?
Solution: Rust
We selected Rust for our high-performance language replacement. It had been used to great success by the Flight Tracking team for high-volume stream processing, and offers the usual benefits of performance, memory safety, and concurrency support. Preliminary testing showed it could easily handle our average rates of 3.5k input messages per second and 1k output messages per second, with significant headroom for catchup should there be an outage in the input data stream.
Post-deployment
This new architecture was released early March 2023. Upon release, it used a single machine for the streamer and three Triton replicas in Kubernetes, which could easily fit onto two nodes. This cut our hardware usage by 75% while still quadrupling our catchup rate.
Since the initial release, we have made several additional changes:
- We released our new multi-airport neural network model. Accommodating the new model was as simple as changing three configuration values: increasing the number of Triton replicas, increasing the number of connections from the streamer to Triton, and increasing the number of concurrent inference requests made by the streamer to Triton.
- We rearchitected our taxi-out prediction infrastructure to match the Rust streamer + Triton pattern.
Over time, we plan to increase the sophistication of our Triton deployments, namely via load-based autoscaling and moving our model repository to a persistent volume (potentially with an MLFlow integration). That said, the shift to Triton has already enabled the release of the neural network model and drastically increased our fault-tolerance and failure recovery capabilities.
I am excited to see what else we can do with Triton and what the future of this project is.
